

Why Deepseek Is Getting Famous: चीनमधील स्टार्टअप कंपनी डीपसीकच्या (Deepseek) नवीन एआय AI मॉडेल्सनी, विशेषतः डीपसीक-R१ या तर्क मॉडेलने, मोठ्या भाषिक मॉडेल्सच्या (LLMs) जगात खळबळ उडवून दिली आहे. या जगात ओपनएआयसारख्या मोठ्या कंपन्यांचे राज्य आहे. Deepseek R1 मॉडेल अनेक चाचण्यांमध्ये ओपनएआयच्या सर्वात चांगल्या मॉडेलच्या बरोबरीचे आहे, आणि तेही खूप कमी खर्चात. यामुळे टेक जगात (तंत्रज्ञानाच्या जगात) एक नवीन बदल झाला आहे.(मोठे भाषिक मॉडेल्स (LLMs) म्हणजे काय? हे खूप मोठे आणि शक्तिशाली कॉम्प्युटर प्रोग्राम असतात, जे माणसांसारखे बोलू आणि लिहू शकतात, आणि अनेक विषयांवर माहिती देऊ शकतात.) २८ जानेवारी २०२५ रोजी, डीपसीकच्या एआय असिस्टंटने (एआय म्हणजे कृत्रिम बुद्धिमत्ता, म्हणजे कॉम्प्युटर स्वतःच माणसासारखे काम करतो) अमेरिकेतील ॲपलच्या ॲप स्टोअरमध्ये ओपनएआयच्या चॅटजीपीटीला मागे टाकून सर्वात जास्त वापरले जाणारे मोफत ॲप्लिकेशन बनण्याचा मान मिळवला.
Deepseek R1|डीपसीक-आर१ ची कामगिरी.
मोठ्या भाषिक मॉडेलची (LLM) कामगिरी मोजण्यासाठी ‘मॅसिव्ह मल्टीटास्क लँग्वेज अंडरस्टँडिंग’ (MMLU) नावाचे एक माप वापरले जाते. MMLU म्हणजे काय? ही एक परीक्षा आहे, ज्यात ५७ वेगवेगळ्या विषयांवर १६,००० प्रश्न विचारले जातात. यावरून कळते की कोणते मॉडेल किती हुशार आहे. काहीजण या परीक्षेला बरोबर मानत नसले, तरी MMLU अजूनही महत्त्वाची परीक्षा आहे.
MMLU मध्ये, डीपसीक-आर१ ची कामगिरी ओपनएआयच्या o1 (आणि o1 ‘प्रो’) मॉडेलच्या जवळपास आहे. डीपसीक-आर१ ने ९०.८ गुण मिळवले, तर o1 ने ९२.३. ६७१ अब्ज पॅरामीटर्सपर्यंत स्केल करता येण्याजोग्या डीपसीक-आर१ ने मेटाच्या प्रमुख Llama 3.1 (४०५ अब्ज पॅरामीटर्स) आणि अँथ्रोपिकच्या प्रसिद्ध क्लॉड ३.५ सोनेट (जून २०२४ मध्ये रिलीज झालेले) मॉडेललाही मागे टाकले. पॅरामीटर्स म्हणजे काय? पॅरामीटर्स म्हणजे मॉडेलची ताकद, जितके जास्त पॅरामीटर्स तितके मॉडेल जास्त शक्तिशाली. MMLU मध्ये माणसांचे सरासरी गुण ८९.८ असतात. म्हणून जग विचार करतंय why deepseek is getting famous.
डीपसीकचा तांत्रिक पेपर मॉडेलच्या GitHub पेजवर उपलब्ध आहे, ज्यात इंग्रजी, कोड, गणित आणि चीनी भाषांसाठी वापरल्या जाणाऱ्या विविध चाचण्यांमध्ये R1 चे गुण दर्शविले आहेत. GitHub पेज म्हणजे काय? GitHub पेज म्हणजे एक वेबसाईट जिथे कॉम्प्युटर प्रोग्राम ठेवले जातात.
भाषेच्या बाबतीत कामगिरी.
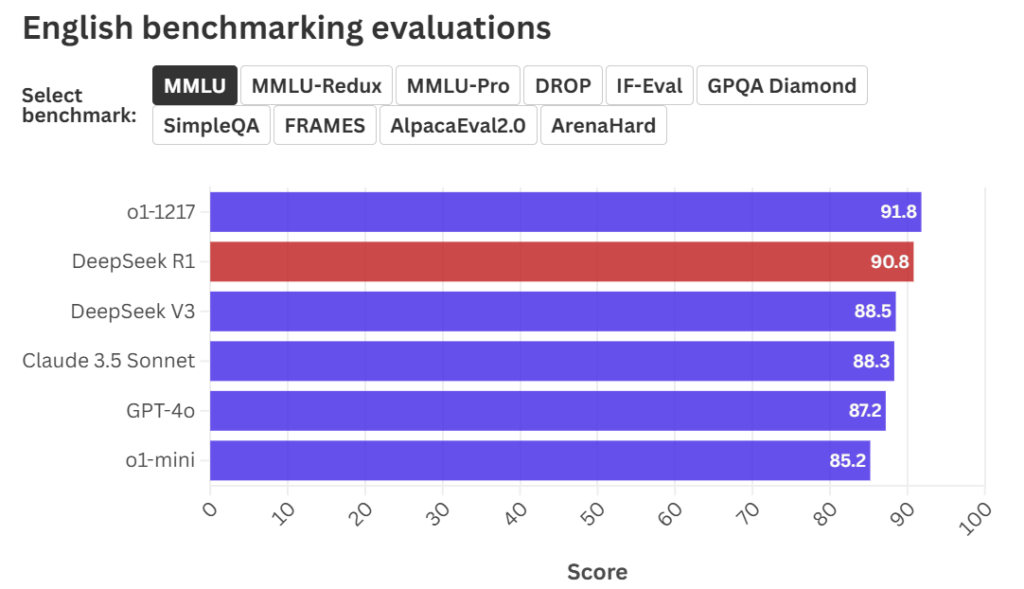
भाषेच्या बाबतीत, R1 ने ओपनएआय आणि अँथ्रोपिकच्या सर्वात शक्तिशाली मॉडेल्सच्या तुलनेत बहुतेक चाचण्यांमध्ये चांगली कामगिरी केली, फक्त SimpleQA मध्ये त्याला ३०.१ गुण मिळाले, जे o1 च्या ४७ गुणांपेक्षा ३५% पेक्षा कमी होते.
कोडिंग कसा करतो.
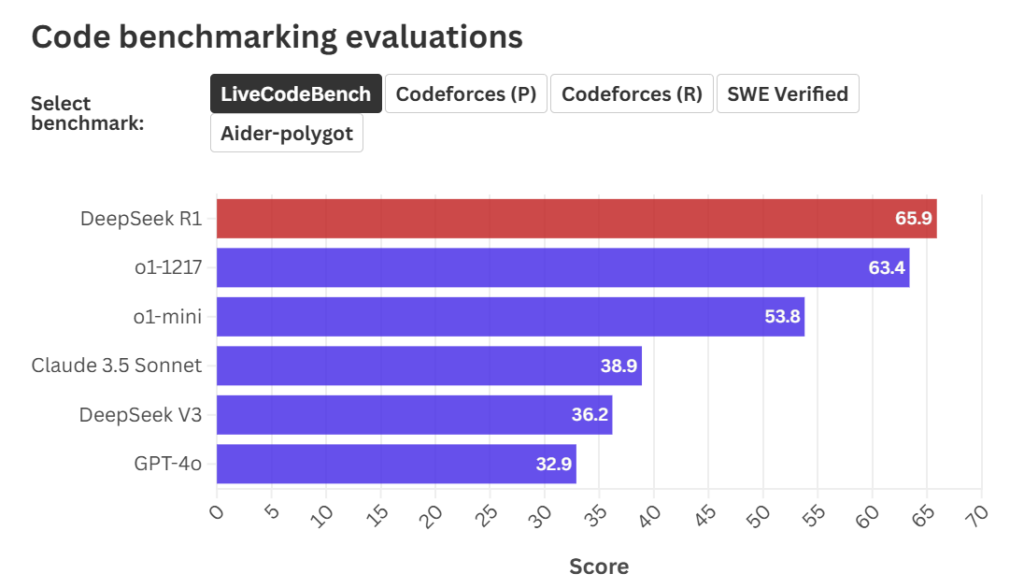
R1 ने LiveCodeBench बेंचमार्किंग टूलमध्ये ६५.९ गुणांसह सर्वोत्तम कामगिरी केली, परंतु इतर चाचण्यांमध्ये त्याची कामगिरी o1 आणि क्लॉड ३.५ सोनेटच्या जवळपास होती. बेंचमार्किंग टूल म्हणजे काय? बेंचमार्किंग टूल म्हणजे वेगवेगळ्या मॉडेल्सची तुलना करण्यासाठी वापरले जाणारे साधन. प्रत्येक चाचणीमध्ये R1 पहिल्या दोन क्रमांकांमध्ये आहे.
कोड म्हणजे काय? कोड म्हणजे कॉम्प्युटरला समजणारी भाषा, ज्याने कॉम्प्युटरला काय करायचे आहे ते सांगतात.
गणिताच्या बाबतीत कामगिरी.
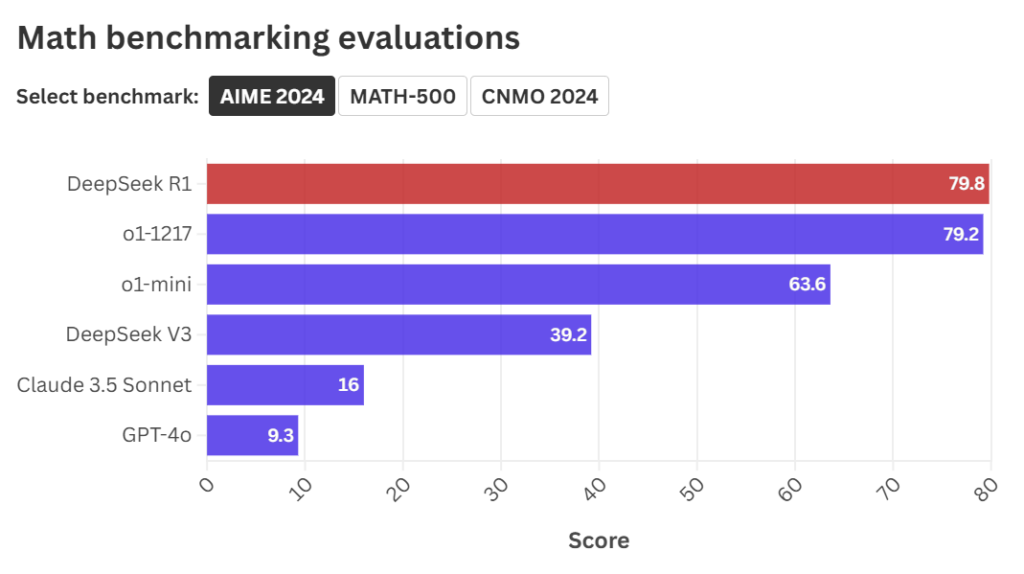
डीपसीक-आर१ ने MATH-500 आणि AIME 2024 मध्ये o1 च्या उत्कृष्ट गुणांनाही मागे टाकले. त्याने MATH-500 मध्ये ९७.३ आणि AIME 2024 मध्ये ७९.८ गुण मिळवले, तर ओपनएआयच्या o1 ने अनुक्रमे ९६.४ आणि ७९.२ गुण मिळवले.
डीपसीक-आर१ ची खर्चिक कार्यक्षमता
या मॉडेलचा सर्वात आकर्षक पैलू म्हणजे त्याची किंमत. डीपसीक-आर१ त्याच्या सर्वात जवळच्या प्रतिस्पर्धी, ओपनएआयच्या o1 च्या तुलनेत खूप कमी किमतीत उपलब्ध आहे. R1 च्या API (ॲप्लिकेशन प्रोग्रामिंग इंटरफेस) चा वापर करण्यासाठी, इनपुट कॉस्ट (मॉडेलच्या टेक्स्टबॉक्समध्ये प्रॉम्प्ट्स टाकण्याचा खर्च, ज्यामुळे प्रतिसाद तयार होतो) १ दशलक्ष टोकनसाठी फक्त $०.५५ आहे, तर o1 साठी $१५ आहे.
API म्हणजे काय? API म्हणजे दोन कॉम्प्युटर प्रोग्राम्स एकमेकांशी बोलण्याचा एक मार्ग.
इनपुट कॉस्ट म्हणजे काय? इनपुट कॉस्ट म्हणजे मॉडेलला प्रश्न विचारण्यासाठी लागणारा खर्च.
टोकन म्हणजे काय? टोकन म्हणजे टेक्स्ट डेटाचा सर्वात लहान भाग (काही अक्षरे), जे LLM द्वारे प्रोसेस करण्यासाठी वापरले जाते. क्लॉड ३.५ सोनेटची इनपुट कॉस्ट १ दशलक्ष टोकनसाठी $३ (R1 च्या जवळपास सहापट) आहे.
ओपनएआयच्या o1, o1-mini, GPT 4o च्या तुलनेत R1 ची आउटपुट कॉस्ट (मॉडेलने तयार केलेल्या उत्तराची किंमत) देखील खूपच परवडणारी आहे. डीपसीक-आर१ ची प्रति दशलक्ष टोकन आउटपुट कॉस्ट ओपनएआयच्या o1 पेक्षा २५ पट स्वस्त आहे.
आउटपुट कॉस्ट म्हणजे काय? आउटपुट कॉस्ट म्हणजे मॉडेलने उत्तर देण्यासाठी लागणारा खर्च.